Dataguard
Dataguard is the management, monitoring and automation software to maintain in sync copies of the main database to protect the database from failures, breakdowns, human errors and data corruption and also providing high availability for critical applications.
It thus helps in maintaining a secondary standby database as an alternative to the primary database.
It is a ship redo (from redo log buffer and redo log files) and apply redo (from standby redo log files), from the primary database to the standby database. The redo can be transmitted to multiple standby databases. The standby databases are in a continuous state of recovery, validating and applying redo data to keep the standby databases in sync with the primary database.
If the standby database gets temporarily disconnected due to a power outage or network issue at the DR site, on restoration of power/or network, it will automatically resynchronize with the primary database.
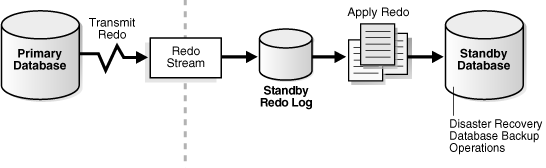
There are 2 separate steps for the replication of data from the primary to the standby database
1. Log Transport - move redo data from the primary to the standby database.
2. Redo Apply - apply the redo data on the standby database.
Log Transport - A redo transport service coordinates the transmission of redo from the primary database to the standby database. At the same time that the LGWR process is processing the redo, a separate dataguard process called the Log Network Server (LNS) process is reading data from the redo log buffer in the SGA and passing it on the Oracle Net Services for transmission to the standby database. On the standby database the Remote File Server (RFS) receives redo from LNS and writes it to a sequential file called a Standby Redo Log (SRL) file. The LNS process supports 2 modes
synchronous and asynchronous transmit.
Synchronous Transport
Also referred to as zero data loss method because the LGWR is not allowed to acknowledge a commit has succeeded until the LNS can confirm that the redo needed to recover the transaction has been written to the standby site.
The phases of the transaction are
The user issues a commit creating a redo record in the redo log buffer, which is then written by LGWR to the online redo log file and waits for confirmation from the LNS.
The LNS reads the same redo record from the redo log buffer and transmits it to the standby database using Oracle Net Services. The RFS receives this redo information at the standby database and writes it to the SRL.
When RFS receives a write complete from the disk, it transmits an acknowledgement back to the LNS process on the primary database which then notifies the LGWR process that redo transmission to the remote server is complete, which in turn sends an acknowledgement to the user that the commit is successful.
Asynchronous Transport
Asynchronous transport eliminates the requirement that the LGWR wait for an acknowledgement from LNS thus eliminating performance issues due to delays between the primary and the standby database. So even if there are delays in transmitting the redo logs from primary to the standby database the LGWR will continue to acknowledge transaction commits without any waits for confirmation from RFS, LNS and LGWR. So if there are delays in transmitting redo data to the standby database and in the meantime, a log switch happens on the primary database, the LNS automatically transitions to reading and sending from the log file instead of the log buffer in the SGA. Once the LNS catches up with the primary for redo log transmission to standby, it automatically switches back to reading from the redo log buffer in the SGA.
The drawback with asynchronous transport is the chances of data loss if a failure on the primary database happens before all redo is transported to the standby database. In that case some committed transactions on the primary database will be lost. This can be reduced by making sure there is enough bandwidth between the primary and the standby database to get the lowest latency possible, thus reducing the chances of data loss on the standby database.
Oracle advanced compression has a feature for redo transport compression for data guard, which can be used in both synchronous (SYNC) transport and asynchronous (ASYNC) transport. This compression feature may have an impact on CPU but will lower network latencies due to bandwidth.
Dataguard automatic gap resolution
In case for any reason the standby database is down or due to some network issues the LNS is unable to transmit redo to the standby database, the two databases go out of sync and a gap develops between the current redo log entry on primary and the redo log entry on the standby database. The primary database continues writing to the online redo log file and on log switch, starts writing to the new online redo log file. Once all redo log files have been written to archiving starts and this results in a large number of archive redo files and online redo log files that need to be processed by LNS thus creating a large log file gap. Data guard uses the ARCH process on the primary database to continuously ping the standby database during an outage. When the standby database is up again the ARCH process queries the control file on the standby database (via RFS) to determine the last complete log file that the standby database received from the primary. The ARCH process then transmits the missing archive log files to the standby database using additional ARCH processes and at the very next log file switch the LNS will attempt and succeed in making a connection to the standby database and begin transmitting current redo log data to standby while the ARCH processes keep working to reduce the gap of the redo in the background. Once the apply process is able to catch up with the current redo logs, the apply process automatically transitions out of reading the archive redo logs into reading the current SRL.

Redo Apply services
There are two methods in which redo is applied to the standby database. Redo Apply (physical standby) and SQL Apply (Logical standby)
Both these methods have the same common features.
- Both synchronize the primary database.
- Both can prevent modifications in the data.
- Both provide a high degree of isolation between the primary and the standby database.
- Both can quick transition the standby database into the primary database.
- Both offer a productive use of the standby database which will have no impact on the primary database.
Physical Standby Database (Redo Apply)
A physical standby database is an exact block for block copy of a primary database. It is maintained as an exact copy through a process call REDO APPLY, in which redo data received from a primary database is continuously applied to the standby database using database recovery mechanisms. So it will always be in sync with the primary database.
Physical standby databases can function either in managed-recovery mode or in read-only mode but not in both modes at the same time. In managed recovery process, when the real time apply feature is enabled, redo can be directly applied to the standby database without the need for waiting for the current standby redo log to be archived. To enable real time apply feature on the physical standby database you need to issue the following sql command which will start the MRP process.
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;
To stop the MRP, following command need to be issued.
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
To run MRP on a specified number of instances
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION INSTANCES 2;
Each apply instance on standby will divide the threads of redo received from the primary among the apply instances to improve scalability of redo apply.
In the above example, 4 threads of redo from the primary is divided by 2 for each apply instance on the standby database.
Status of MRP can be checked from the following query
SELECT STATUS FROM V$MANAGED_STANDBY WHERE PROCESS=’MRP0′;
Media recovery does parallel recovery for very high performance. It comprises a media recovery coordinator (MRP0) and multiple parallel apply processes (PR0?). The coordinator manages the recovery session, merges the REDO by SCN and multiple instances (if in a RAC environment) and parses REDO into change mappings partitioned by the apply process. The apply processes read data blocks, assemble redo changes from mappings and then apply redo changes to the data blocks.
This method allows you to be able to use the standby database in read only fashion. Active dataguard achieves read consistency by the use of a query SCN. The media recovery process on the standby database advances the query SCN after all dependent changes in a transaction have been successfully applied. The query SCN is exposed to the user via the current SCN column of the v$database view. Read only use will only be able to see data upto the query SCN and thus the standby database can be open in read only mode while media recovery is active, which makes this an ideal reporting database.
REDO apply can be used both in SYNC and ASYNC methods and is isolated from I/O physical corruption. Corruption detection checks occur at the following key interfaces
On the primary during redo transport - LGWR, LNS, ARCH use the DB_ULTRA_SAFE parameter.
On the standby database redo apply - RFS, ARCH, MRP, DBWR use DB_LOST_WRITE_PROTECT parameters.
If dataguard detects any corruption, it will automatically fetch new copies of data from the primary using gap resolution process in the]hope that the data on the primary database is corruption free.
The key features of this solution are
- Complete application and data transparency - no datatype or other restrictions.
- High performance, less maintenance complexity.
- End to end validation before redo apply, including any corruptions due to lost writes.
- Able to be utilized for up-to-date read-only queries and reporting while providing DR.
- Able to execute rolling database updates.
Logical Standby (SQL Apply)
SQL apply uses logical standby process (LSP) to coordinate the apply of changes to the standby process. SQL apply requires more processing than redo apply as the processes that do the SQL apply read the standby redo logs (SRL) and mine redo by converting it to logical change records and then building SQL transactions and then applying SQL to the standby database and since there is more processing involved it requires more CPU, memory and I/O than redo apply.
SQL Apply does not support all datatypes such as XML in object relational format and Oracle supplied types such as Oracle spatial, Oracle intermedia and Oracle text.
The benefit of SQL apply is that the database is open for read write while the SQL apply process is still active. While you cannot make any changes to the replica data you can insert, modify and delete data from local tables and schemas that have been added to the database. You can create ddl objects like materialized views and local indexes.
This makes the database ideal to be used by reporting tools etc.
The key features of SQL apply are
- A standby database that is open for read write while SQL apply is still active.
- A dataguard setting that prevents modification of data that is being maintained by SQL apply.
- Ability to apply rolling database upgrades beginning Oracle 11g onwards using the KEEP IDENTITY clause.
Protection Modes
The three protection modes in oracle databuard are
Maximum Performance
For maximum performance redo has to be applied in ASYNC mode so that LGWR does not have to wait for an acknowledgement from the standby database.
Only drawback in this method is some data loss can occur if the primary database fails before a full resync between primary and standby.
Maximum Availability
The first priority in this method is maximum availability and and the second priority is zero loss protection. For this it requires the dataguard to be in SYNC mode. In case the standby database in unavailable for data replication, there is a NET_TIMEOUT parameter. The primary database will wait for NET_TIMEOUT time before it gives up on the standby and continues processing transactions. Later when the connection has been established, the primary will automatically resync with the standby database.
When the NET_TIMEOUT value reaches, the LGWR process disconnects from the LNS process, acknowledges the transaction commit and proceeds with transaction processing. This continues until the current online redo log is complete and the LGWR switches to the next online redo log. At that time a new LNS process is started and an attempt is made to connect to the standby server. If this succeeds the new online redo log is sent to standby as normal. If not the LGWR disconnects from the LNS process until the next log switch. Thus this process repeats for every log switch till the time the standby is available and a connection is established. If any archive logs have been created during this time, the ARCH process will continuously ping the standby database waiting until it becomes online.
Here also there is a chance of data loss if the primary and secondary go down and there is no re sync between the two databases.
Maximum Protection
The priority in this mode is no data loss even if it severely hampers the performance of the primary database. It uses SYNC redo transport and primary will not issue a commit until it receives an acknowledgement from the standby database that all redo has been written on the standby. The primary will stall if for any reason it does not receive an acknowledgement from the standby database. This guarantees complete data protection and to avoid a single point of failure it is advised to have at least two separate standby databases in this mode on two different network infrastructures so that even if one standby database fails the dataguard will still be running on one active standby thus preventing any stall or failure on the primary database.
There are two events in a dataguard setup
switchover - a planned event
failover - an unplanned event
Switchover
When you want to perform certain maintenance tasks on the primary such as a patch or database upgrade activity or a hardware change like adding more memory or cpu on the primary database server, you can switchover to the stanby database in which case the standby will now become the new primary database.
The following activities happen during a switchover
1. When switchover starts, the primary database is notified about this event.
2. All users are disconnected from the primary database.
3. A special redo log record is generated which specifies the end of redo (EOR).
4. The primary database is converted to a standby.
5. Once the standby database is applies the last EOR record, guaranteeing no data loss, the standby is converted to the primary database.
Now the roles of both the databases are reversed. It is important that both the databases receive the EOR record so both databases know when the next redo will be received.
Failover
It is an unplanned event. Here the primary database does not get EOR notification record as happens during a switchover. The failover can be manual or an automatic process. Here the DBA has full control over the failover process. In automatic failover, oracle dataguard fast start failover feature can automatically detect a problem on the primary and failover to the standby. This process takes about 15 to 25 seconds.
Split Brain scenario in oracle dataguard
Split brain is when both the primary and standby think that each one is a primary database. This scenario can be avoided with dataguard fast start failover, in which the failed primary cannot open without first receiving permission from the dataguard observer process. The observer will know that a failover has occurred and will refuse the original primary to open. The observer process will reinstate the failed primary as the standby database for the new primary database making it impossible to have a split brain condition.
Dataguard management
There are 3 ways to manage data guard
- SQLPlus
- Dataguard broker - a distributed management tool that centralizes management and uses the DGMGRL command line
- Enterpise Manager - a GUI to the dataguard broker replacing the DGMGRL command line.
In the next post I have given give the step by step scripts and explanations for a physical data guard setup between primary and standby database.
Link for the same is below
When duplicating the database on the standby database if you get the following error
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS =============
RMAN-00571: ===========================================================
RMAN-03002: failure of Duplicate Db command at 01/25/2010 16:02:45
RMAN-03015: error occurred in stored script Memory Script
RMAN-03009: failure of backup command on ORA_DISK_1 channel at 01/25/2010 16:02:45
ORA-17627: ORA-12545: Connect failed because target host or object does not exist
ORA-17629: Cannot connect to the remote database server You will need to check the alias of ORCL on the auxiliary or standby database for the target database.
It should match with the alias given on the target database.
Since I already had an existing ORCL instance on the auxiliary database I had given an alias ORCLTGT to the target database tns entry.
I have dropped the ORCL database on the auxiliary (standby) database and have removed the entry of ORCL alias pointing to the local ORCL database from the tnsnames.ora file.
Add a new ORCL alias which will now have the tns pointing to the target server ORCL database
Oracle 19c dataguard configuration
How to start MRP0 process in active dataguard
TARGET database - 192.168.56.101
AUXILIARY database - 192.168.56.102
ORCL=
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.56.101)(PORT = 1522))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = orcl)
)
)
References
Dataguard ArchitectureOracle 19c dataguard configuration
How to start MRP0 process in active dataguard
Thought for the day
“Restrain your voice from weeping
and your eyes from tears,
for your work will be rewarded,”
declares the Lord.
Jeremiah 31:16
No comments:
Post a Comment