A common scenario in an OLTP systems is the growth of data and its management.
The below is an example of an OLTP system, say a banking system, where there are customers opening accounts in the bank and transacting daily causing the disk utilization to keep going high.
This space utilization can be managed by adding disk space on a continuous basis, deleting unwanted data, shrinking tables after a large delete operation, dropping backup and temporary tables, archiving data on a continuous bases. OS level cleanups etc. The aim is to maintain an optimum balance between a frequent adding disk space and managing the existing space in the best possible way to minimize cost of new hardware for disk space, its maintenance etc. and also enhance the performance of the existing system by removing unwanted data from the system.
The below is an archiving scenario to attain the above target to the best possible.
For this case study we create the CUST tablespace which is of a fixed size of 5M and with AUTOEXTEND feature OFF to simulate a fixed size hard disk and its usage. Based on the actual data the size can be extrapolated to GB/TB to suit the environment the archiving will be used for.
In this tablespace we create the CUST user which will have the CUST schema objects.
The customer and transaction data is stored in the CUST schema in the CUSTOMER and DAILY_TRANSACTIONS tables..
Assuming daily customers are getting added and daily, they are doing debit and credit transactions there is a continuous growth of data in the CUST tablespace, causing disk space utilization to reach 100 % on a regular basis, thus making archiving a viable solution for this space management problem.
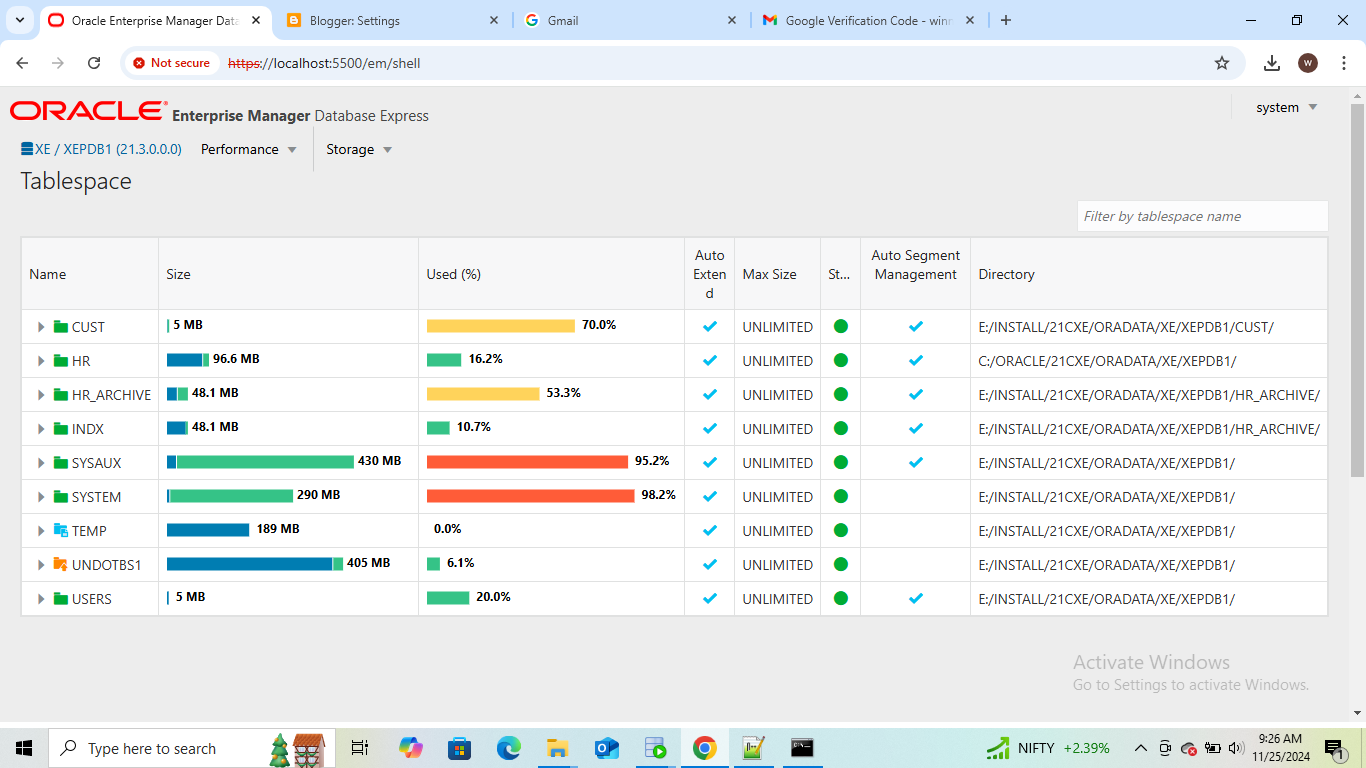
For the aove In OEM the CUST tablespace shows as 70% full after 5 days of growth in data.
SELECT SUM(BYTES)/1024/1024 FROM DBA_SEGMENTS WHERE OWNER = 'CUST';
3.5
Assuming daily 20 customers are joining the bank and each customer has 100 transactions there is going to be a utilization of disk space until the disk reaches maximum space capacity and any further data inserts are going to give error like
Error report -
ORA-01654: unable to extend index CUST.PK_TRANS by 64 in tablespace CUST
ORA-06512: at "CUST.ARCHIVE_MACHINE_DATA_PUMP", line 71
ORA-06512: at "CUST.ARCHIVE_MACHINE_DATA_PUMP", line 71
ORA-06512: at line 2
01654. 00000 - "unable to extend index %s.%s by %s in tablespace %s"
*Cause: Failed to allocate an extent of the required number of blocks for
an index segment in the tablespace indicated.
*Action: Use ALTER TABLESPACE ADD DATAFILE statement to add one or more
files to the tablespace indicated.
SELECT SUM(BYTES)/1024/1024 FROM DBA_SEGMENTS WHERE OWNER = 'CUST';
4

We can add more disk space on a regular basis. But it wont be the most effective and viable solution from performance and economic point of view. So archiving can be considered to give some relief to the space pressure and thus minimize the frequency of disk space addition.
We create the CUST schema and insert dummy data to test this archiving scenario.

Script to do bulk data insert into CUSTOMER and DAILY_TRANSACTIONS tables
Setting up the archive rules
In the archive schema below is the entry for the archive rules
| TXT_RULE_CD | NUM_RULE_PRIORITY | TXT_RULE_DESC | TXT_RULE_QUERY | TXT_ACTIVE_FLG | TXT_PRIMARY_TABLE | TXT_ARCHIVE_TABLE_LIST | TXT_TBL_OWNER |
|---|---|---|---|---|---|---|---|
| 100003 | 1 | Archive daily_transactions from trade date - 3 | SELECT rowid FROM CUST.DAILY_TRANSACTIONS WHERE TRANS_DATE < (SELECT TRDE_DT - 3 FROM CUST.CURR_TRDE_DT) | Y | DAILY_TRANSACTIONS | DAILY_TRANSACTIONS | CUST |
| 100004 | 1 | Archive customers not existing in daily_transactions | SELECT rowid FROM CUST.CUSTOMER ct WHERE NOT EXISTS (SELECT 1 FROM CUST.DAILY_TRANSACTIONS dt WHERE ct.CUST_ID = dt.CUST_ID) | Y | CUSTOMER | CUSTOMER | CUST |
Automating the archiving machine
With the above information, we can create a scheduler job which will be running the archive machine in the background. This job will continuously keep polling in the background and if there is any data in CUST schema older than 3 days it will archive that data.
When the ARCHIVE_BTN is pressed (updated to START) in ARCHIVE_CNTRL table, we are ready to run the archive machine. Now if we run the archive machine by calling RUN_ARCHIVE_MACHINE, it will run in an infinite loop and check the value of ARCHIVE_BTN in ARCHIVE_CNTRL table. If the value of this is START, it will call PR_ARCHIVE_MACHINE. The archive machine will check the archive rule table for any archive jobs that are pending or any new jobs, and start the archive process. Once the archive process is complete, the archive machine will sleep for 30 seconds. After that it will again check if the archive button is pressed (ARCHIVE_BTN updated to START) , If YES it will call the archive process again which will check for pending or new jobs for archiving and the cycle will repeat itself in an infinite loop. To stop the archive machine we need to update the ARCHIVE_BTN in the ARCHIVE_CNTRL table to STOP. Now in the next cycle, the RUN_ARCHIVE_MACHINE process will again check the value of ARCHIVE_BTN. Since it is updated to STOP it will exit and the archving process and the archive scheduler will come to a HALT. In an ideal scenario if the daily number of customers and transactions count is fixed then the archiving script can continuously run in the background to archive data and no additional disk space will need to be added. But in actual this may not be the case and there will be a steady increase in the count of customers and transactions. But with a suitable archiving policy in place the need for adding new disk space can reduce appreciably thus resulting in a cost effective solution. Below are some statistics to put the archiving case study in perspective. Without any archving, if 20 customers are having 100 transactions daily about 9 days the CUST tablespace (in actual it may be the data disk or partition) reaches its max threshold capacity . If data is inserted beyond 9 days it gives the error
With no growth in data and a 3 day archive pplicy in place, there will be no need for any additional disk space.
ORA-01654: unable to extend index CUST.PK_TRANS by 64 in tablespace CUST
Below are some statistics on the space utilization for CUST tablespace
| No of days | No of customers/day | No of transactions per day | Total transactions | Tablespace utilization | Tablespace utilization percentage |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 2.5M | 50% |
| 3 Days | 20 | 100 | 6000 | 3M | 60% |
| 5 Days | 20 | 100 | 10000 | 3.5M | 70% |
| 8 Days | 20 | 100 | 16000 | 4M | 80% |
With no archiving and no data growth
Total Transaction count - 18000 @2000 transactions/day for 9 days before the tablespace utilization reaches its maximum.
| In CUST schema | |
|---|---|
| Date | No of transactions per day |
| 15-MAY-0025 00:00:00 | 2000 |
| 14-MAY-0025 00:00:00 | 2000 |
| 13-MAY-0025 00:00:00 | 2000 |
| 12-MAY-0025 00:00:00 | 2000 |
| 11-MAY-0025 00:00:00 | 2000 |
| 10-MAY-0025 00:00:00 | 2000 |
| 09-MAY-0025 00:00:00 | 2000 |
| 08-MAY-0025 00:00:00 | 2000 |
| 07-MAY-0025 00:00:00 | 2000 |
| Total | 18000 |
With a 5% increase in data daily, rest of the parameter remaining the same,
and with no archiving the tablespace reaches its threshold space utilization in 7 days before you get the error -
ORA-01654: unable to extend index CUST.PK_TRANS by 64 in tablespace CUST
Total transaction count - 17120 transactions.
| In CUST schema | |
|---|---|
| Date | No of transactions per day |
| 06-MAY-0025 00:00:00 | 2820 |
| 05-MAY-0025 00:00:00 | 2680 |
| 04-MAY-0025 00:00:00 | 2560 |
| 03-MAY-0025 00:00:00 | 2440 |
| 02-MAY-0025 00:00:00 | 2320 |
| 01-MAY-0025 00:00:00 | 2200 |
| 30-APR-0025 00:00:00 | 2100 |
| Total | 17120 |
With a 5% increase in data daily, rest of the parameter remaining the same,
and with the 3 days archivng policy, the tablespace reaches its thershold space utilization in 13 days before you get the error - ORA-01654: unable to extend.
Data for 4 days is in the main CUST schema and for 9 days prior to that in the archiving schema).
Total transactions 35360 (12740 in the main CUST schema having 4 days data and 22620 transactions having 9 days data in the ARCHIVE schema)
In archive schema per day count of records
| In CUST schema | |
|---|---|
| Date | No of transactions per day |
| 29-APR-0025 00:00:00 | 3420 |
| 28-APR-0025 00:00:00 | 3260 |
| 27-APR-0025 00:00:00 | 3100 |
| 26-APR-0025 00:00:00 | 2960 |
| Total | 12740 |
| In Archive schema | |
|---|---|
| Date | No of transactions per day |
| 25-APR-0025 00:00:00 | 2820 |
| 24-APR-0025 00:00:00 | 2680 |
| 25-APR-0025 00:00:00 | 2820 |
| 24-APR-0025 00:00:00 | 2680 |
| 23-APR-0025 00:00:00 | 2560 |
| 22-APR-0025 00:00:00 | 2440 |
| 21-APR-0025 00:00:00 | 2320 |
| 20-APR-0025 00:00:00 | 2200 |
| 19-APR-0025 00:00:00 | 2100 |
| Total | 22620 |
And for the ideal scenario, with no data growth and a proper archiving policy, the data can be archived without the need for any additional disk space addition.
This has been done for a 30 day period, for 20 customers per day and 100 transactions per customer and the space utilization has been maintained between 70% and 85% in the CUST tablespace.
With no growth in data and a 3 day archive pplicy in place, there will be no need for any additional disk space.
Below is the data for a 30 day sample period.
In actual since there will always be a steady growth of customers and transactions, in the above case study, with no archiving we will need to add disk space after every 7 days. With a suitable archiving policy this will extend to 13 days.Thus we see that with the combination proper disk space addition and a good archiving policy, we can reduce the disk space utilization and thus optimize the cost of the database infrastructure.
| In CUST schema | |
|---|---|
| Date | No of transactions per day |
| 14-JUN-0025 00:00:00 | 2000 |
| 13-JUN-0025 00:00:00 | 2000 |
| 12-JUN-0025 00:00:00 | 2000 |
| 11-JUN-0025 00:00:00 | 2000 |
| Total | 8000 |
| In Archive schema | |
|---|---|
| Date | No of transactions per day |
| 10-JUN-0025 00:00:00 | 2000 |
| 09-JUN-0025 00:00:00 | 2000 |
| 08-JUN-0025 00:00:00 | 2000 |
| 07-JUN-0025 00:00:00 | 2000 |
| 06-JUN-0025 00:00:00 | 2000 |
| 05-JUN-0025 00:00:00 | 2000 |
| 04-JUN-0025 00:00:00 | 2000 |
| 03-JUN-0025 00:00:00 | 2000 |
| 02-JUN-0025 00:00:00 | 2000 |
| 01-JUN-0025 00:00:00 | 2000 |
| 31-MAY-0025 00:00:00 | 2000 |
| 30-MAY-0025 00:00:00 | 2000 |
| 29-MAY-0025 00:00:00 | 2000 |
| 28-MAY-0025 00:00:00 | 2000 |
| 27-MAY-0025 00:00:00 | 2000 |
| 26-MAY-0025 00:00:00 | 2000 |
| 25-MAY-0025 00:00:00 | 2000 |
| 24-MAY-0025 00:00:00 | 2000 |
| 23-MAY-0025 00:00:00 | 2000 |
| 22-MAY-0025 00:00:00 | 2000 |
| 21-MAY-0025 00:00:00 | 2000 |
| 20-MAY-0025 00:00:00 | 2000 |
| 19-MAY-0025 00:00:00 | 2000 |
| 18-MAY-0025 00:00:00 | 2000 |
| 17-MAY-0025 00:00:00 | 2000 |
| 16-MAY-0025 00:00:00 | 2000 |
| Total | 52000 |
Create the CUST schema objects
Creaing the CUST tablespace. As SYSTEM user.
CREATE TABLESPACE CUST
DATAFILE 'E:\install\21cXE\oradata\XE\XEPDB1\CUST\CUST.dbf'
SIZE 5M AUTOEXTEND OFF
LOGGING ONLINE PERMANENT BLOCKSIZE 8192
EXTENT MANAGEMENT LOCAL
UNIFORM SIZE 524288
SEGMENT SPACE MANAGEMENT AUTO;
CREATE USER CUST IDENTIFIED BY CUST;
GRANT CREATE SESSION TO CUST;
GRANT CONNECT TO CUST;
GRANT CREATE TABLE TO CUST;
GRANT CREATE PROCEDURE TO CUST;
GRANT CREATE ANY TYPE TO CUST;
GRANT CREATE ANY SEQUENCE TO CUST;
ALTER USER CUST DEFAULT TABLESPACE CUST;
ALTER USER CUST TEMPORARY TABLESPACE TEMP;
GRANT CREATE VIEW, ALTER SESSION, CREATE SEQUENCE TO CUST;
GRANT CREATE SYNONYM, CREATE DATABASE LINK, RESOURCE , UNLIMITED TABLESPACE TO CUST;
As HR user give the following grants to CUST user
GRANT REFERENCES ON HR.COUNTRIES TO CUST;
GRANT REFERENCES ON HR.REGIONS TO CUST;
Since the archiving process does a table delete from the main schema, we need to shrink the table size after a delete operation of archiving has happened. This is very important to reclaim the used space.
For that as SYS user connected to the PDB containing the schema data to be archived, we need to give the following grant to the archiving schema.
GRANT ALTER ANY TABLE TO HR_ARCHIVE;
ALTER TABLE CUST.DAILY_TRANSACTIONS ENABLE ROW MOVEMENT;
ALTER TABLE CUST.DAILY_TRANSACTIONS SHRINK SPACE CASCADE;
ALTER TABLE CUST.CUSTOMER ENABLE ROW MOVEMENT;
ALTER TABLE CUST.CUSTOMER SHRINK SPACE CASCADE;
CREATE TABLE CURR_TRDE_DT
( TRDE_DT DATE
)
TABLESPACE CUST ;
INSERT INTO CURR_TRDE_DT VALUES ('13-NOV-24');
GRANT SELECT ON CURR_TRDE_DT TO HR_ARCHIVE;
DROP TABLE CUSTOMER;
CREATE TABLE CUSTOMER
(
CUST_ID NUMBER,
CUST_NAME VARCHAR2(100),
PHONE_NUMBER VARCHAR2(20 BYTE),
EMAIL VARCHAR2(30 BYTE),
ADDR_LINE_1 VARCHAR2(500),
ADDR_LINE_2 VARCHAR2(500),
ADDR_LINE_3 VARCHAR2(500),
COUNTRY_ID CHAR(2 BYTE),
REGION_ID NUMBER,
GENDER VARCHAR2(20)
) TABLESPACE CUST;
ALTER TABLE CUSTOMER ADD CONSTRAINT PK_CUST PRIMARY KEY (CUST_ID);
ALTER TABLE CUSTOMER ADD CONSTRAINT FK_CUST_CNTRY FOREIGN KEY (COUNTRY_ID) REFERENCES HR.COUNTRIES;
ALTER TABLE CUSTOMER ADD CONSTRAINT FK_CUST_REGN FOREIGN KEY (REGION_ID) REFERENCES HR.REGIONS;
DROP TABLE DAILY_TRANSACTIONS;
CREATE TABLE DAILY_TRANSACTIONS
(
TRANS_ID NUMBER,
TRANS_DATE DATE,
CUST_ID NUMBER,
TRANS_AMT NUMBER,
TRANS_CRNCY VARCHAR2(3),
TRANS_IND VARCHAR2(10),
ACCT_NO VARCHAR2(50),
BNK_NAME VARCHAR2(100),
BNK_LOCATION VARCHAR2(100),
BANK_IFSC VARCHAR2(100)
) TABLESPACE CUST;
ALTER TABLE DAILY_TRANSACTIONS ADD CONSTRAINT PK_TRANS PRIMARY KEY (TRANS_ID, TRANS_DATE);
ALTER TABLE DAILY_TRANSACTIONS ADD CONSTRAINT FK_TRANS_CUST FOREIGN KEY (CUST_ID) REFERENCES CUSTOMER;
Script to insert sample record in CUSTOMER table
INSERT INTO CUSTOMER
(
CUST_ID,
CUST_NAME,
PHONE_NUMBER,
EMAIL,
ADDR_LINE_1,
ADDR_LINE_2,
ADDR_LINE_3,
COUNTRY_ID,
REGION_ID,
GENDER
)
VALUES
(
100001,
'NOVAK DJOKOVIC',
'+381 (0)11 3148648',
'djoko@gmail.com',
'Bulevar Arsenija Carnojevica 54a',
'11070 New Belgrade',
'Republic of Serbia',
'SR',
3,
'MALE'
);
INSERT INTO DAILY_TRANSACTIONS
(
TRANS_ID,
TRANS_DATE,
CUST_ID,
TRANS_AMT,
TRANS_CRNCY,
TRANS_IND,
ACCT_NO,
BNK_NAME,
BNK_LOCATION,
BANK_IFSC
)
VALUES
(
200001,
'09-NOV-2041',
100001,
25000,
'USD',
'CR',
'SRNVK3148648',
'BANK OF SERBIA',
'New Belgrade',
'SRBK0008956'
);
Data Pump to do a bulk data insert.
The below script is inserting data in the CUSTOMER and DAILY_TRANSACTIONS tables assuming 20 customers are daily having 100 transactions for a period of 8 days.
The parameters for DAY_COUNT, CUSTOMER_COUNT and TRANSACTION_COUNT can be changed as per the size of the tablespace or the disk size to suit your testing scenario.
CREATE OR REPLACE PROCEDURE ARCHIVE_MACHINE_DATA_PUMP AS
CURSOR CUST
IS
SELECT *
FROM CUSTOMER
WHERE CUST_ID = 100001;
customer_id NUMBER ;
trans_id NUMBER ;
DAY_COUNT CONSTANT INTEGER := 20;
CUSTOMER_COUNT CONSTANT INTEGER := 20;
TRANSACTION_COUNT INTEGER := 100;
DAY_RESET_COUNT NUMBER:= 0;
dt_trde_dt DATE;
CURSOR TRANS
IS
SELECT *
FROM DAILY_TRANSACTIONS
WHERE TRANS_ID = 200001;
BEGIN
SELECT MAX(CUST_ID)
INTO customer_id
FROM CUSTOMER;
SELECT MAX(TRANS_ID)
INTO trans_id
FROM DAILY_TRANSACTIONS;
SELECT TRDE_DT
INTO dt_trde_dt
FROM CURR_TRDE_DT;
FOR i IN 1 .. DAY_COUNT
LOOP
dt_trde_dt := dt_trde_dt + 1;
DAY_RESET_COUNT := DAY_RESET_COUNT + 1;
TRANSACTION_COUNT := TRANSACTION_COUNT * 1.05;
UPDATE CURR_TRDE_DT
SET
TRDE_DT = dt_trde_dt;
FOR rec IN CUST
LOOP
FOR i IN 1 .. CUSTOMER_COUNT
LOOP
customer_id := customer_id + 1;
INSERT INTO CUSTOMER
(
CUST_ID,
CUST_NAME,
PHONE_NUMBER,
EMAIL,
ADDR_LINE_1,
ADDR_LINE_2,
ADDR_LINE_3,
COUNTRY_ID,
REGION_ID,
GENDER
)
VALUES
(
customer_id,
rec.CUST_NAME || '-' || customer_id,
rec.PHONE_NUMBER,
rec.EMAIL,
rec.ADDR_LINE_1 || customer_id,
rec.ADDR_LINE_2,
rec.ADDR_LINE_3,
rec.COUNTRY_ID,
rec.REGION_ID,
rec.GENDER
);
FOR rec IN TRANS
LOOP
FOR i IN 1 .. TRANSACTION_COUNT
LOOP
trans_id := trans_id + 1;
INSERT INTO DAILY_TRANSACTIONS
(
TRANS_ID,
TRANS_DATE,
CUST_ID,
TRANS_AMT,
TRANS_CRNCY,
TRANS_IND,
ACCT_NO,
BNK_NAME,
BNK_LOCATION,
BANK_IFSC
)
VALUES
(
trans_id,
dt_trde_dt,
customer_id,
rec.TRANS_AMT + trans_id,
rec.TRANS_CRNCY,
rec.TRANS_IND,
rec.ACCT_NO,
rec.BNK_NAME,
rec.BNK_LOCATION,
rec.BANK_IFSC
);
END LOOP; --} transction 10 loop
END LOOP; --} transaction main loop
END LOOP; --} customer 10 loop
END LOOP; --} CUSTOMER MAIN LOOP
COMMIT;
IF DAY_RESET_COUNT = 3
THEN
DAY_RESET_COUNT := 0;
SYS.DBMS_LOCK.SLEEP(100);
END IF;
END LOOP; --} END trade date loop
END ARCHIVE_MACHINE_DATA_PUMP;Scripts for starting and running the archive machine
Create the archive controller to start and stop the archive machine in the HR_ARCHIVE schema.
CREATE TABLE HR_ARCHIVE.ARCHIVE_CNTRL
( ARCHIVE_BTN VARCHAR2(10 BYTE)
) TABLESPACE HR_ARCHIVE ;
INSERT INTO ARCHIVE_CNTRL VALUES ('START');
UPDATE ARCHIVE_CNTRL SET ARCHIVE_BTN = 'STOP';
UPDATE ARCHIVE_CNTRL SET ARCHIVE_BTN = 'START'; -- after this update need to run the rchive scheduler job
GRANT EXECUTE ON SYS.DBMS_LOCK TO HR_ARCHIVE;
CREATE OR REPLACE PROCEDURE RUN_ARCHIVE_MACHINE AS
v_program_name VARCHAR2(100) := 'RUN_ARCHIVE_MACHINE';
v_table_name VARCHAR2(100) := NULL;
ARCHIVE_EXCEPTION EXCEPTION;
v_err_desc VARCHAR2(500);
v_error_code NUMBER := PKG_ARCHIVE.SUCCESS;
v_archv_btn VARCHAR2(10) := 'STOP';
v_loop_cntr NUMBER := 0;
BEGIN
WHILE TRUE
LOOP --{
SELECT ARCHIVE_BTN
INTO v_archv_btn
FROM ARCHIVE_CNTRL;
IF v_archv_btn = 'START'
THEN
v_loop_cntr := v_loop_cntr + 1;
PR_ARCHIVE_MACHINE;
COMMIT;
v_err_desc := 'Calling archive machine ' || v_loop_cntr;
PR_ARCHIVE_ERROR_LOG(v_program_name, v_table_name ,v_err_desc, SQLCODE , SQLERRM , SYSDATE , USER, v_error_code);
ELSE
EXIT;
END IF;
DBMS_LOCK.SLEEP (30);
END LOOP; --}
END RUN_ARCHIVE_MACHINE;
We give to give the below grants to the HR_ARCHIVE user.
Execute privileges' on DBMS_SCHEDULER package owned by SYS user on the archive schema PDB to HR_ARCHIVE user.
Create job privileges' to HR_ARCHIVE user.
GRANT EXECUTE ON SYS.DBMS_SCHEDULER TO HR_ARCHIVE;
GRANT CREATE JOB TO HR_ARCHIVE;
BEGIN
DBMS_SCHEDULER.create_job (job_name => 'ARCHIVE_SCHEDULER',
job_type => 'STORED_PROCEDURE',
job_action => 'RUN_ARCHIVE_MACHINE',
start_date => SYSDATE,
enabled => TRUE);
END;
BEGIN
DBMS_SCHEDULER.stop_job (job_name => 'ARCHIVE_SCHEDULER',
);
END;
God's Word for the day
If you assist a thief, you only hurt yourself.
You are sworn to tell the truth, but you dare not testify.
Fearing people is a dangerous trap,
but trusting the Lord means safety.
Proverbs 29:24-25
Gospel teachings of Jesus
Jesus walks on the water
But when the disciples saw him walking on the sea, they were terrified,
saying, "It is a ghost!". And they cried out in fear.
But immediately Jesus spoke to them and said, "Take heart, it is I.
do not be afraid."
Peter answered him, "Lord, if it is you, command me to come to you
on the water." He said, "Come." So Peter got out of the boat,
started walking on the water, and came toward Jesus.
But when he noticed the strong wind, he became frightened,
and beginning to sink, he cried out, "Lord save me!"
Jesus immediately reached out his hand and caught him,
saying to him, "You of little faith, why did you doubt?"
When they got into the boat, the wind ceased.
And those in the boat worshipped Him, saying
"Truly you are the Son of God."
Mathew 14:26-33
No comments:
Post a Comment